Cost Aware Speech Enhancement
Train a model that learns how many microphones to look at before producing an output.
In this paper, we present a method for jointly-learning a microphone selection mechanism and a speech enhancement network for multi-channel speech enhancement with an ad-hoc microphone array. The attention-based microphone selection mechanism is trained to reduce communication-costs through a penalty term which represents a task-performance/ communication-cost trade-off. While working within the trade-off, our method can intelligently stream from more microphones in lower SNR scenes and fewer microphones in higher SNR scenes. We evaluate the model in complex echoic acoustic scenes with moving sources and show that it matches the performance of models that stream from a fixed number of microphones while reducing communication costs.
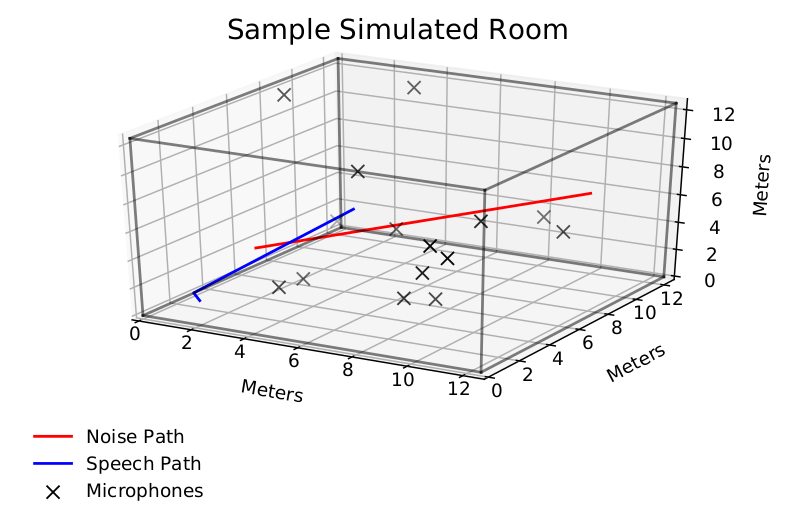
Motivated by the fact that in a multi-channel scenarios not all microphones will be required to achieve good performance. So, we can reduce complexity by only processing data from a subset of devices. We construct a toy scene below where a speech source moves through an ad-hoc array.
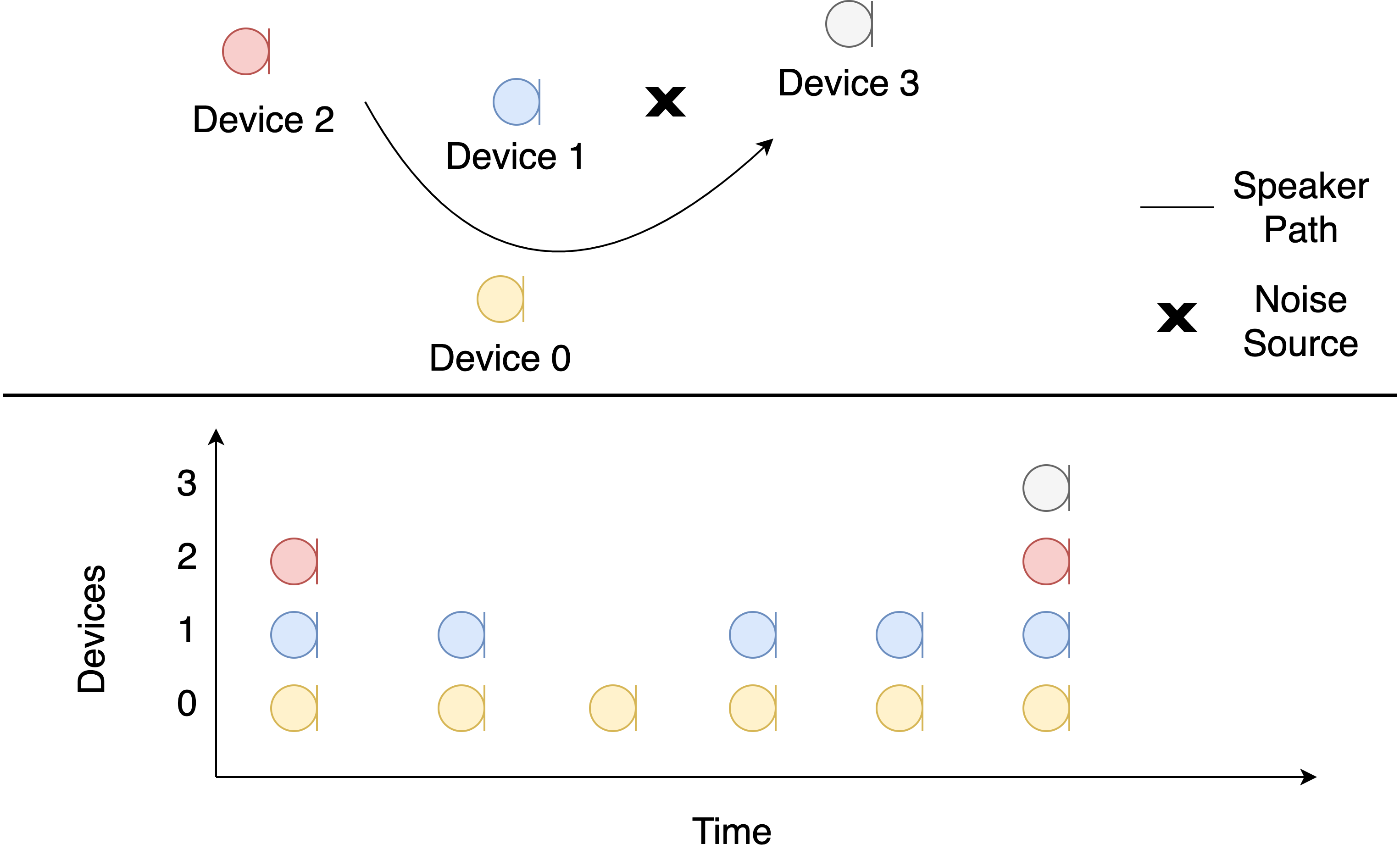
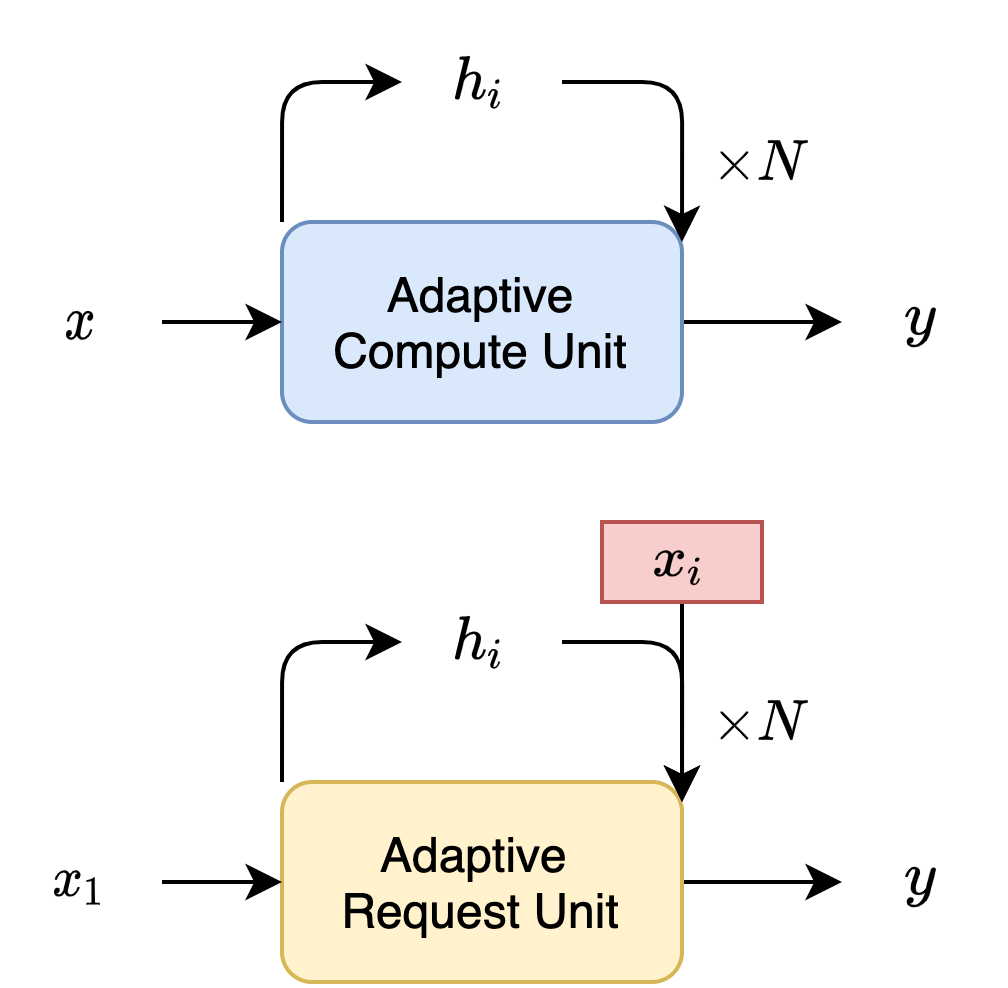
However, selection is not a differentiable operation making it difficult to use with a neural network. To get around this we formulate the Adaptive Compute Time RNN originally proposed by Alex Graves. Our reformulation iteratively requests new data in addition to updating it’s hidden state. We show the original Adaptive Compute Unit on the top in blue and our modification below in yellow.
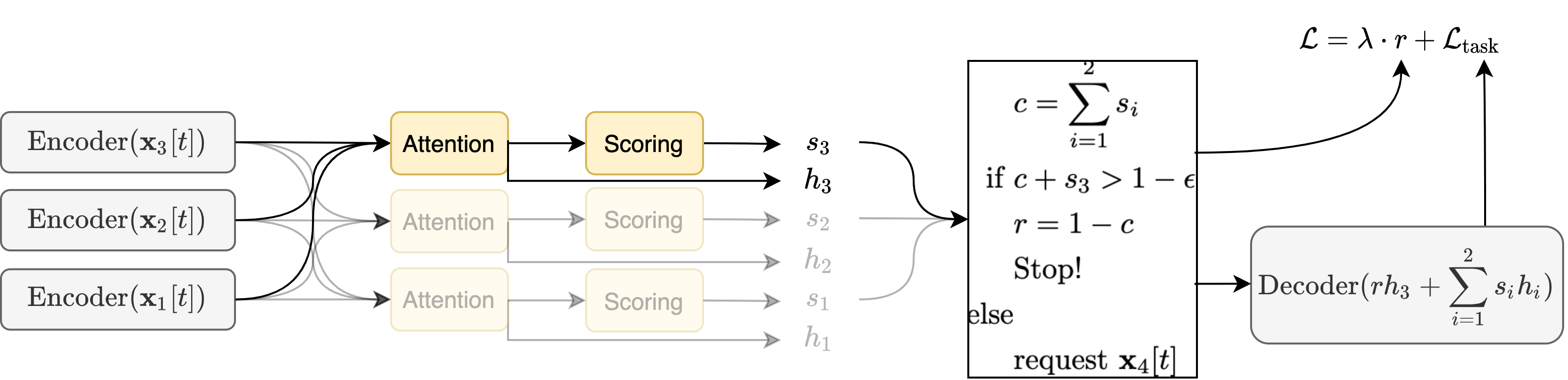
Using this adaptive request unit, we can run a speech enhancement model on an ad-hoc microphone array and adaptively decide how many microphones to stream from. Below, we depict the model at particular time step after having processed three microphones. The attention unit aggregates all information from the requested microphones and the scoring unit produces a value which we compare to a budget. If the value is within the budget then another microphone is requested. Otherwise, the model ceases requesting and moves on to the next point in time. The model is encouraged to request fewer microphones by minimizing the remainder, r. Minimizing this remainder maximizes the scores assigned to all previous sensors which encourages the model to exhaust it’s budget sooner.
The full model is made up of a multi-channel encoding stage, a request and aggregation stage, and a single channel decoding stage. The pipeline is shown in the model figure above. We tested this model in simulated echoic rooms with moving noises and source like the one shown above.
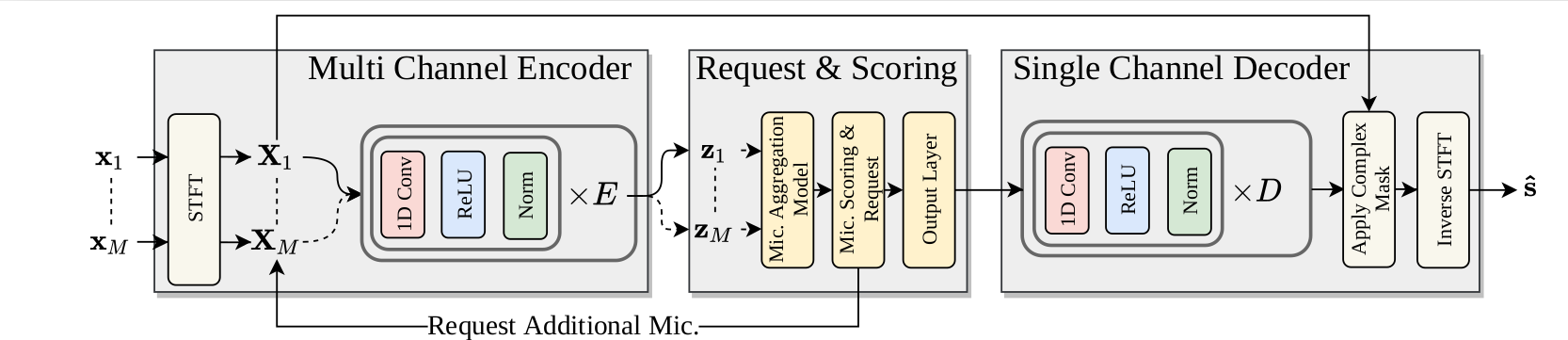
The novelty of our method is two-fold. First, using a learning-based mechanism for microphone selection and second, learning that mechanism jointly with the enhancement network. We think there are many potential applications for these adaptive request units and hope to continue investigating them. Below are some randomly selected enhancement results from the trained network.
Randomly Selected Demos
| Random Scene 1 | Random Scene 2 | |
| Clean | ||
| Microphone 1 | ||
| Microphone 2 | ||
| Microphone 3 | ||
| Microphone 4 | ||
| Prediction |
Our paper is available on arxiv here. Our code is available on GitHub here!